How Did AI Models Perform for Hurricane Humberto?
As we discussed for Typhoon Ragasa, it is worthwhile to examine how AI models performed for high-profile or high-impact TCs, before conducting a full verification at the end of the season. The latest TC we will look at is Humberto, which did not impact land but was our 2nd Category 5 of the 2025 Atlantic season, and also was interesting because of its interaction with Hurricane Imelda (which we will look at in a later post).
As a reminder, these are the AI models examined:
AIEN: AIFS Ensemble Control
AISN: AIFS Deterministic
PANG: Pangu Weather
AURO: Aurora
GRPC: GraphCast
GDMN: Google’s Deepmind FNV3 Ensemble Mean
We also compare with operational GFS (AVNO) and HAFS-A (HFSA), two key models typically used for TC prediction.
Track
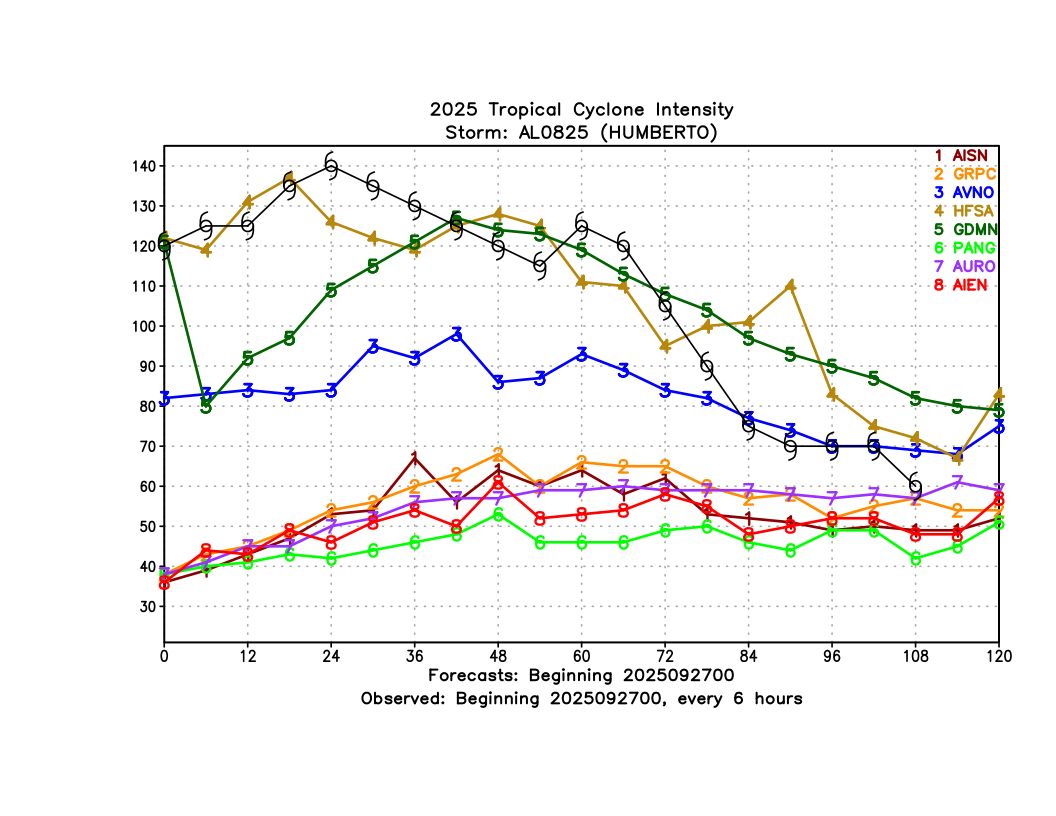
In contrast to some of the recent storms we have seen, where AI models dominated on track skill compared to dynamical models, the AI models actually did not perform as well overall for Hurricane Humberto compared to operational GFS especially (Figure 1). The one AI model that was competitive at most forecast hours was Google Deepmind/FNV3 (GDMN on the plots), with better skill than GFS at Days 1-2 and comparable skill at Day 5. GraphCast was also comparable to GFS and HAFS-A at times, but did considerably worse at early lead times.
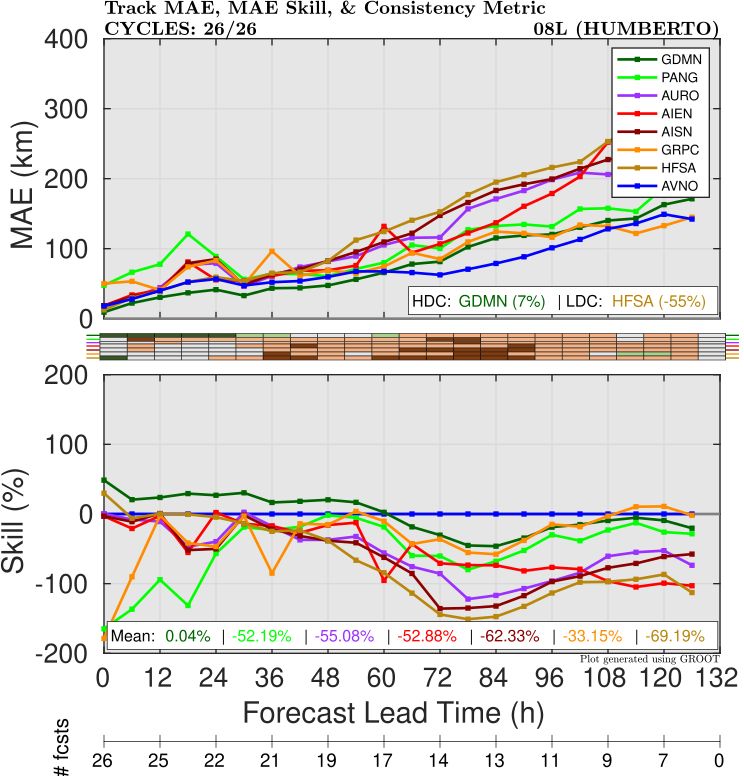
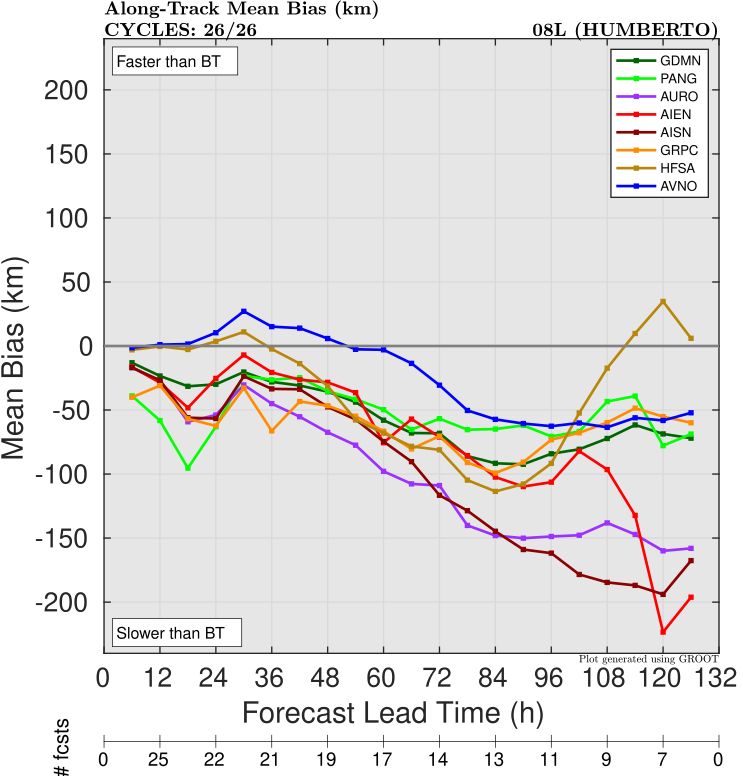
A breakdown of the track error shows that most of the AI models suffered from a slow bias (Figure 2), leading to a large along-track error compared to GFS. AIFS (both single run and ensemble control versions) had particularly large errors at Day 5.
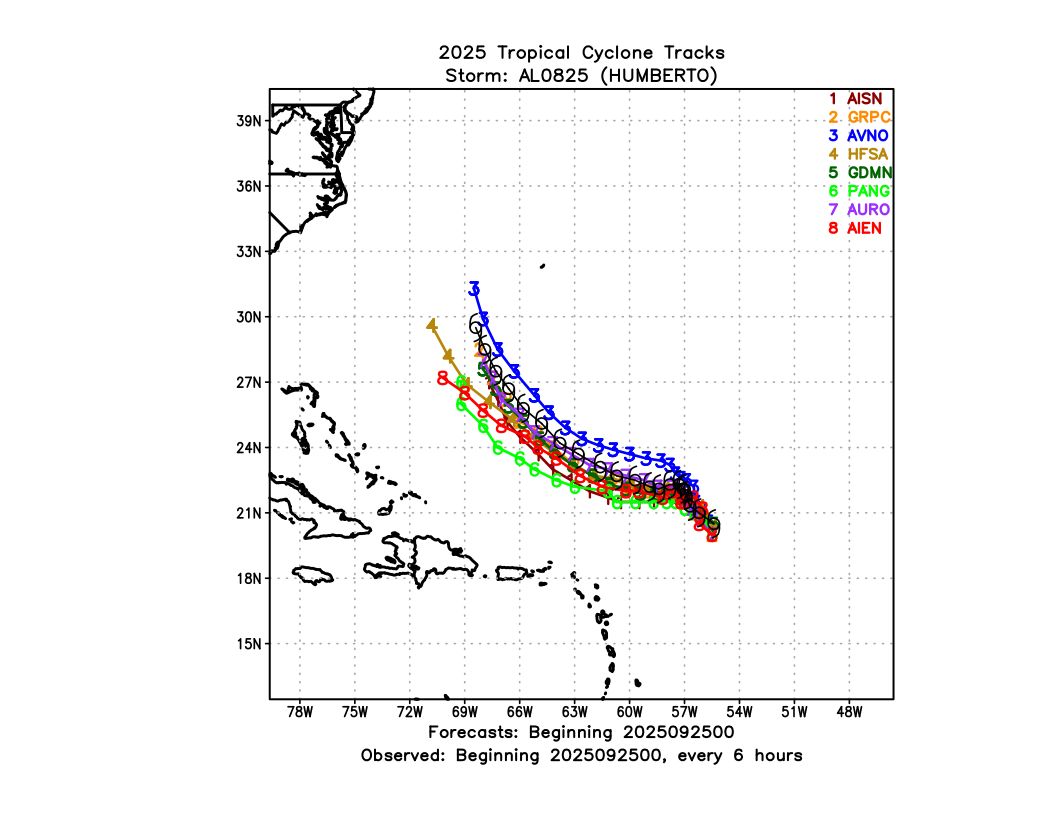
An example track forecast (from one of the earlier cycles while Humberto was still developing) illustrates this speed issue. For this cycle, almost all of the AI models were too slow and to the left of track (though GraphCast and Deepmind were close). GFS on the other hand had a better speed though it was too far to the right (a common bias for this model). This was a complex track case with lots of moving parts thanks to interaction with a front and also Imelda to the west, so it remains to be seen whether this along-track bias is something that will plague AI models in other cases.
Intensity
For intensity, as with other cases, most AI models did not have very good skill (Figure 4). The one notable exception was Google Deepmind (FNV3), which actually had the lowest intensity errors (even lower than HAFS-A!) at almost all lead times.
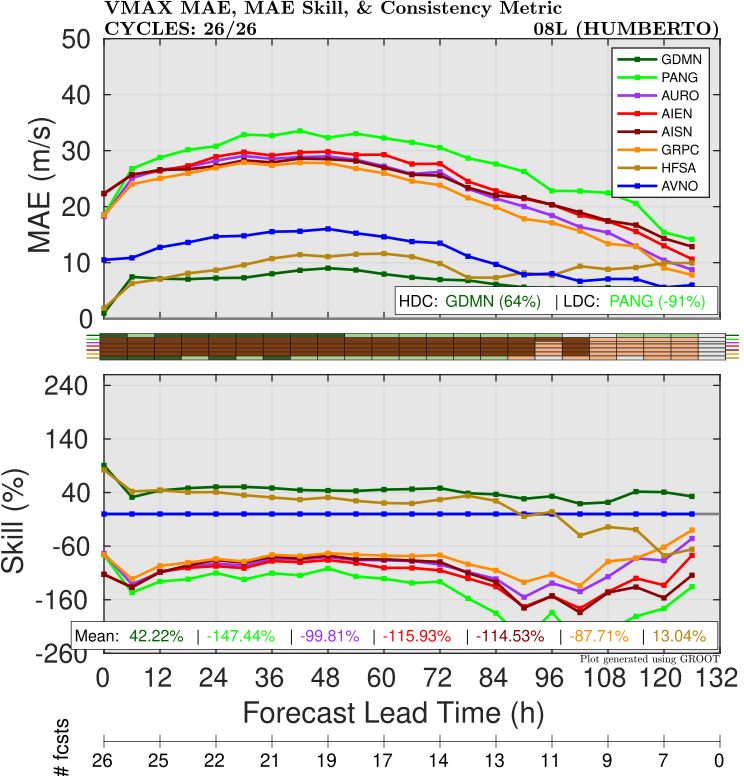
This intensity skill was pretty remarkable considering that Humberto rapidly intensified to a Category 5 hurricane. While FNV3 did not fully capture the rapid intensification, even the ensemble mean did show a faster intensification rate from its early forecasts than any of the AI or dynamical models (Figure 5).
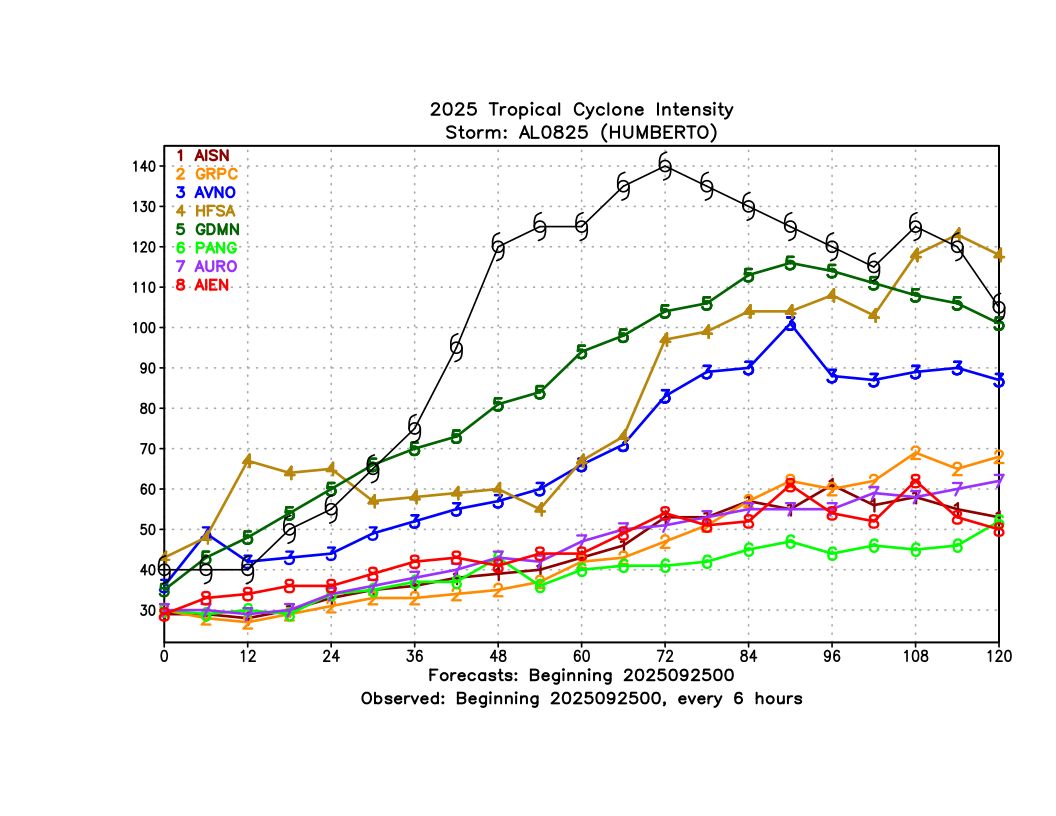
Humberto did illustrate one weakness of current AI modeling for intensity. Once it got very strong (Category 4-5), FNV3 (GDMN) was not able to maintain the initial intensity that it was given, and dropped off to an intensity that was ~50 knots too weak 6 hours after initialization (Figure 6). It eventually recovered somewhat around 36 hours later, but this bias led to a large error in the 12-24 hour range. It is not immediately clear what is causing this issue - it could be that the low resolution is leading to this dropoff despite the bias correction. The fact that DeepMind had comparable skill to HAFS overall at 12-24 hours despite this issue suggests that AI intensity skill should continue to improve as better bias correction techniques and higher resolution datasets are developed.