A Tricky Setup: Atlantic Model Forecast Discussion 9-24-2025
A complex forecast situation is unfolding across the Atlantic in the wake of Gabrielle. Tropical Storm Humberto has formed northeast of the Caribbean, and is moving to the west-northwest. The complexity comes from a potential interaction with a second system, 94L, currently moving towards Hispaniola. Here are a few of the complexities:
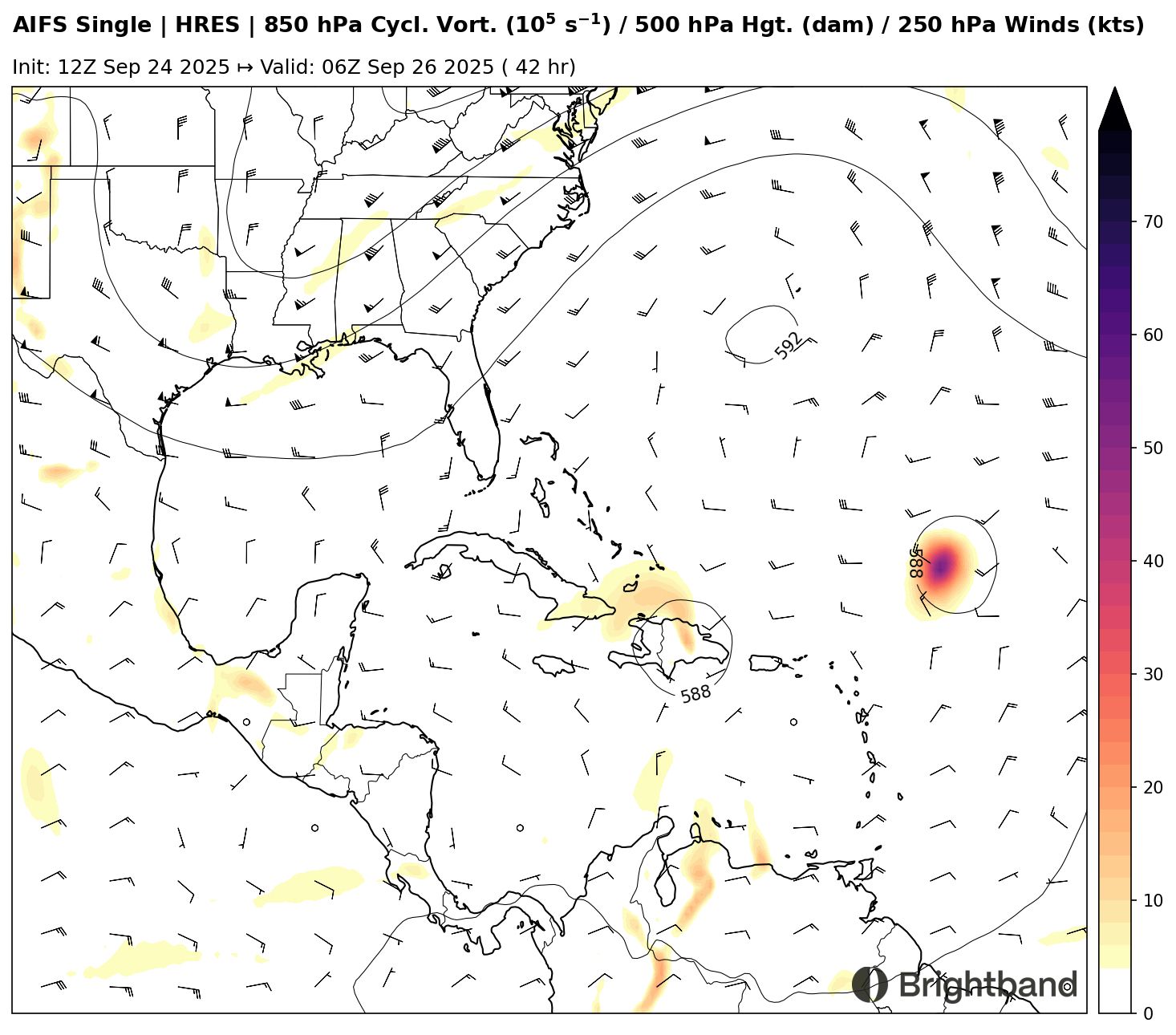
The vorticity of 94L is forecast to move across the mountainous terrain of Hispaniola (Figure 1). This can disrupt circulations and form new ones. It’s not clear how well AI-based models will handle this evolution, so that will be interesting to track.
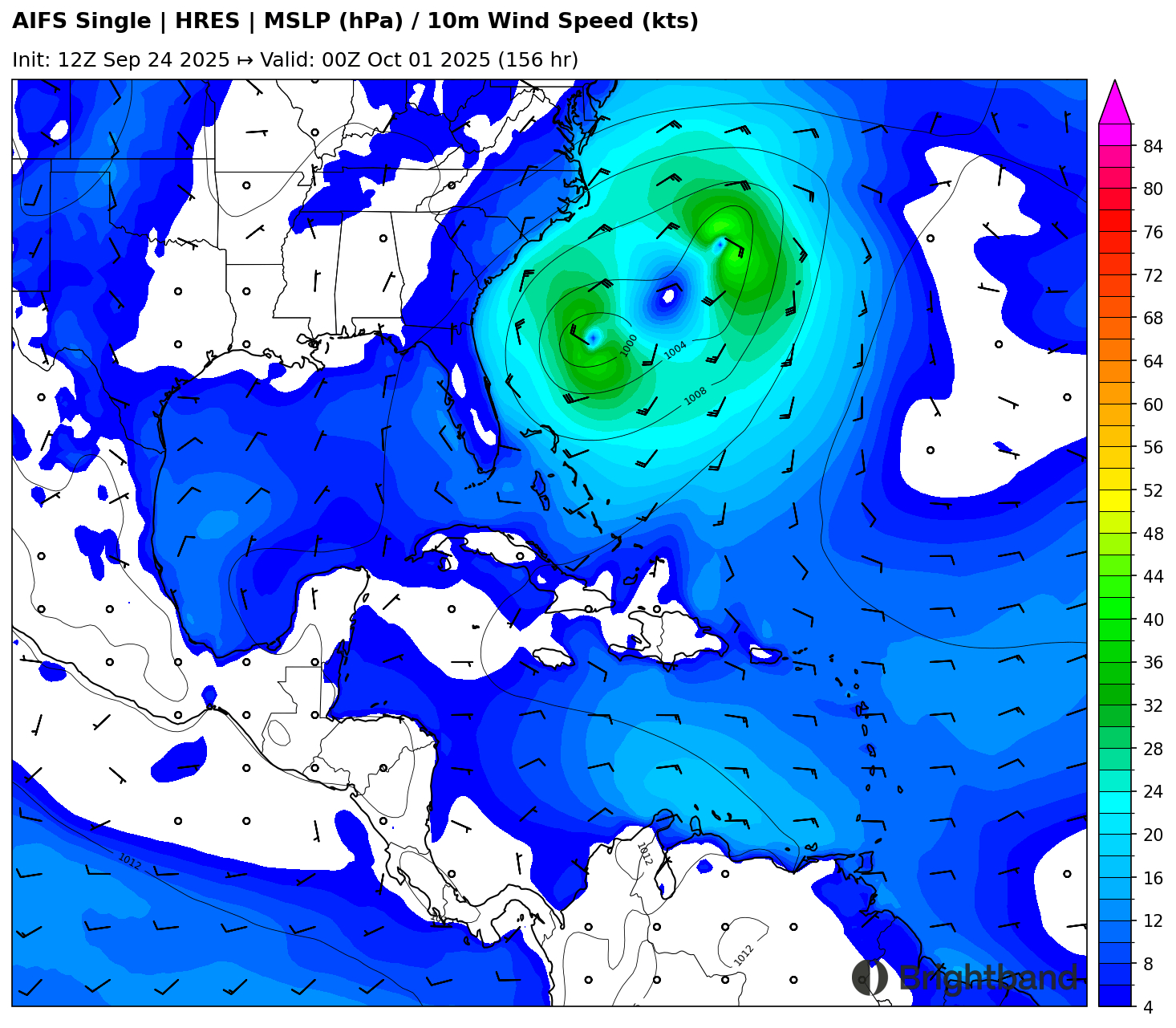
94L will be interacting with an upper low over the Southeast US. This will try to tug the forming storm north and maybe even northwest, and if it moves fast enough it could move inland before the potential interaction with Humberto (which will be discussed next).

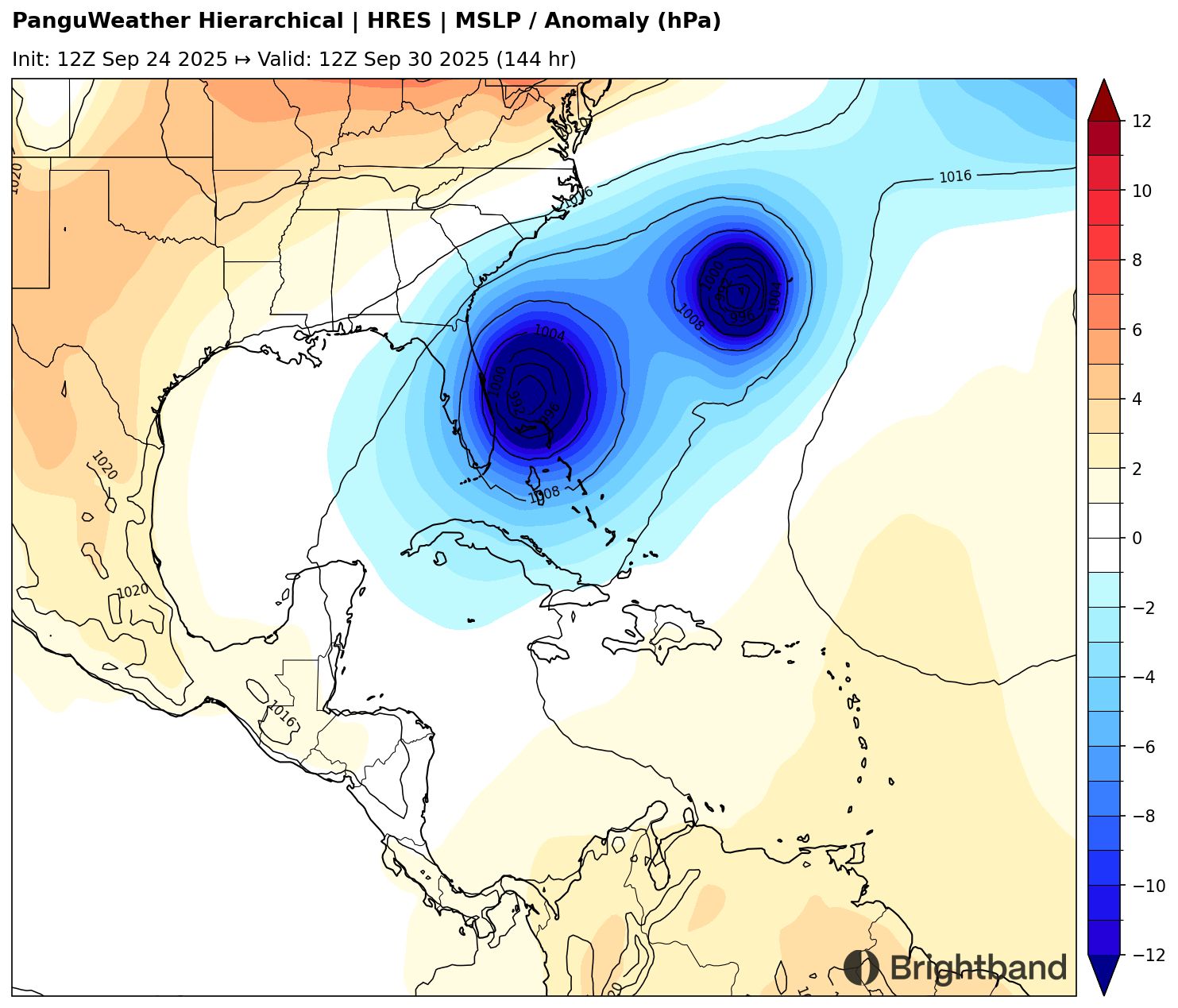
The most complex part of the forecast comes from the possible direct interaction of 94L and Humberto. These so-called “Fujiwhara” interactions (https://www.weather.gov/news/fujiwhara-effect) are rare, and can produce complex and unpredictable tracks. This is made even more complex by the upper low mentioned above. Usually in the Atlantic, one of the 2 storms dominates and eventually shears and absorbs the other one. It’s very rare to have two storms of comparable magnitude interacting and rotating around each other, but that is what some models are depicting right now (Figure 3). The “tug” from Humberto could pull 94L to the east and prevent it from hitting the coast if they are close enough to each other.
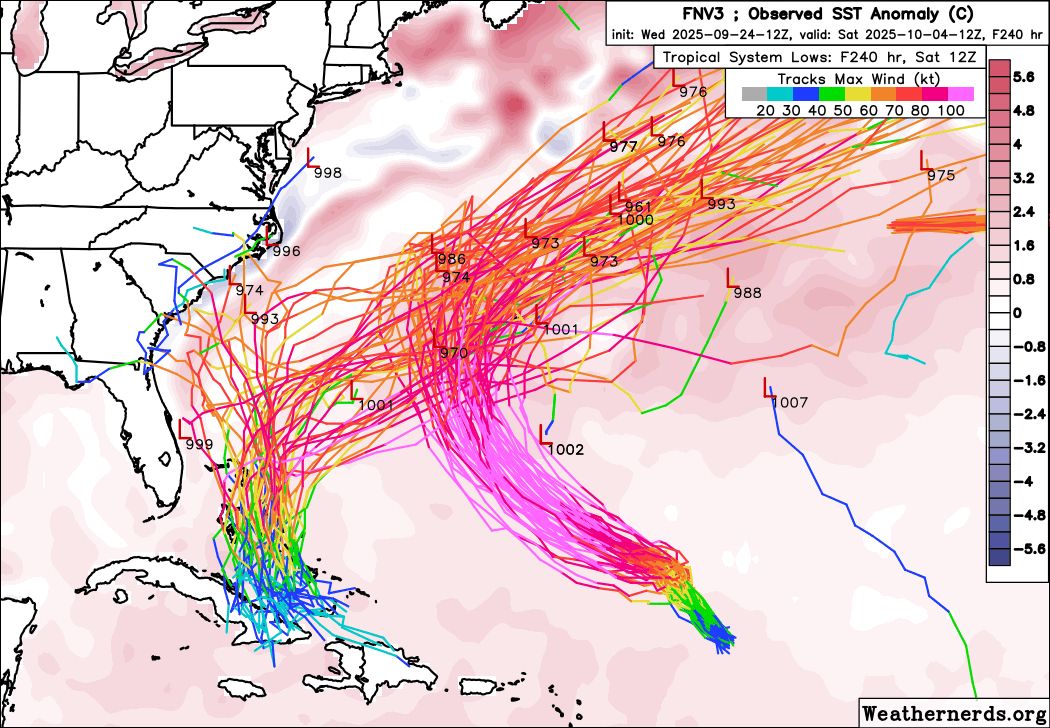
As a result of this uncertainty, ensembles show a wide variety of solutions. The Google DeepMind ensemble (Figure 4) shows a clear recurve for Humberto, likely as a strong hurricane. However, it is split between a landfall and a recurve for 94L. It is not at all clear if AI training datasets will allow the model to handle these situations well, since as mentioned these sorts of direct interactions are very rare. This will be a case where large model errors are likely, and it will be interesting to evaluate the performance of the AI models after the fact.